
TensorFlow Python 버전은 한국자료가 많지만
Javascript 버전은 많이 사용하지 않아서
텐서플로우 공식홈페이지에 기재되어있는 블로그를
직접 테스트하고 번역하려한다.
원본 글을 보려면 아래 링크를 클릭.
https://blog.tensorflow.org/2018/04/a-gentle-introduction-to-tensorflowjs.html
A Gentle Introduction to TensorFlow.js
blog.tensorflow.org
시작하기에 앞서 본 글은 18년 4월에 게시되었기때문에 패키지를 최신버전으로 설치해야한다.
텐서플로우 자바스크립트버전을 사용하려면 대표적으로 두 가지 방법이 있는데
하나는 브라우저단에서 설치하는 것이고 하나는 노드의 패키지매니저를 통해 설치하는 것이다.
방법 1. 브라우저단에서 설치하기
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>html 문서에 스크립트 태그에 위와 같이 입력하고
로컬에서 브라우저를 실행하여 F12를 눌러 콘솔로 패키지를 잘 가져왔는지 확인하자.
방법 2. node package manager를 사용하여 설치하기
npm install @tensorflow/tfjs-node
사용하는 에디터에서 npm명령어로 패키지를 설치해도 된다.
위 두 가지 방법은 많은 부분을 설명에서 생략했다. 이해가 잘 되지 않는다면
웹 기초와 node.js와 패키지 매니저 정도를 학습하고 참고하길 바란다.
참고로 이 글은 tensorflow.js의 튜토리얼을 진행하는 것이므로
텐서플로우와 머신러닝, 딥러닝에 대한 기초적인 부분은 설명을 생략한다.
- Tensors (The building blocks)
스칼라 텐서를 선언하는 법.
const tensor = tf.scalar(2);
다 차원 텐서들을 만들어보자.
const input = tf.tensor([2,2]);
텐서의 크기를 알아볼 수 있다.
const tensor_s = tf.tensor([2,2]).shape;
0으로 초기화된 텐서를 얻을 수 있다.
const input = tf.zeros([2,2]);
- Operators
텐서들을 사용하기 위해서는 텐서들에게 연산자를 만들어 줘야한다. 제곱을 연산해보자.
const a = tf.tensor([1,2,3]);
a.square().print();
tensorflow.js에서는 체인 연산자를 허용한다.
그래서 x2의 값은 [4, 9, 16]이 아니라 [1, 16, 81]이다.
const x = tf.tensor([1,2,3]);
const x2 = x.square().square();
- Tensor Disposal
대개 쉽게 코딩하려고 텐서를 많이 선언하게 되는데 그러다 보면 쓰지않는 텐서들이 생기기 마련이다.
이를 처리하기 위해서 아래와 같은 함수를 쓴다.
const x = tf.tensor([1,2,3]);
x.dispose();
위와 같이 안쓰는 텐서는 메모리를 잡아먹게 되어 있고
그렇다고 매번 dispose( ) 함수를 호출하는 것 또한 정말 번거로운 일이다.
그래서 tensorflow.js는 tidy( ) 라는 함수를 제공한다.
function f(x)
{
return tf.tidy(()=>{
const y = x.square();
const z = x.mul(y);
return z
});
}우리는 z의 값을 받고 나면 y에 잡고 있는 메모리는 잘 해제될 것이다.
- Optimization problem
SGD, Adam등과 같은 많은 옵티마이저들이 있지만 이들은 각각 속도와 정확성이 다르다.
tensorflow.js는 많은 옵티마이저들 중에서도 가장 중요한 옵티마이저들을 지원하고 있다.
예를 들어 f(x) = x⁶+2x⁴+3x²+x+1의 식은 아래의 이미지와 같이 표현할 수 있다.
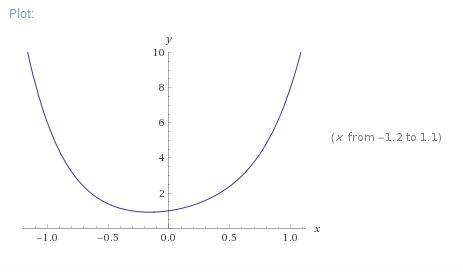
위 그래프에서 x가 -0.5에서 0 사이의 구간에서 작은 y값을 가진다는 것을 알 수 있다.
이제 실제로 옵티마이저를 사용해서 값을 정확히 확인해볼 것이다.
일단 위의 함수를 정의하자.
function f(x) {
const f1 = x.pow(tf.scalar(6, 'int32')); //x^6
const f2 = x.pow(tf.scalar(4, 'int32')).mul(tf.scalar(2)); //2x^4
const f3 = x.pow(tf.scalar(2, 'int32')).mul(tf.scalar(3)); //3x^2
const f4 = tf.scalar(1); //1
return f1.add(f2).add(f3).add(x).add(f4);
}참고로 pow는 power라는 뜻인데 이는 영어로 제곱을 뜻한다.
자바스트립트에서는 Math.pow(밑, 지수)행태로 쓰이나,
우리는 파라미터를 텐서로 받았기 때문에
밑.pow(지수)형태로 사용할 것이다.
그리고 지수의 파라미터 또한 스칼라인것을 알 수 있다.
이제 이 함수를 반복시켜서 계속해서 더 작은 값을 찾을 수 있다.
처음 최솟값으로 업데이트할 변수 'a = 2' 라는 값으로 초기화한다.
그리고 learning rate을 정의한다.
이것은 최솟값이 얼마나 빨리 도달한건가에 대한 값인데
너무 작으면 점프를 작게해서 반복되는 횟수동안에 도달하지 못 할 수 도 있고
값이 너무 커서 점프를 크게 해버리면 계속해서 작은 값을 찾지 못하고 발산해버린다.
예제에서는 adam optimizer를 사용한다.
function minimize(epochs, lr) {
let y = tf.variable(tf.scalar(2)) //initial value
const optim = tf.train.adam(lr); //gadient descent algorithm
for(let i = 0; i < epochs; i++) {
optim.minimize(()=>f(y));
}
return y
}
minimize(200, 0.9).print();epochs = 200을 대입하고 lr(learning rate) = 0.9를 대입하고 최적화한 결과로
y가 최솟값을 갖게 하는 x의 값으로 -0.16092407703399658라는 값을 구했다.
- 간단한 신경망구현
이제 우리는 'XOR-비선형연산자'를 만들어 볼것이다.
먼저, 두 개의 입력에 하나의 출력을 가지는 트레이닝셋을 만들어야 한다.
우리는 각 반복마다 4개의 데이터를 가진 하나의 세트묶음을 넣어서 학습시킬것이다.
xs = tf.tensor2d([[0, 0], [0, 1], [1, 0], [1, 1]])
ys = tf.tensor2d([[0], [1], [1], [0]])그러고 두 개의 dense layer를 만든다.
이렇게만 할 경우 비선형적 특성을 이용할 수 없다.
그러므로 각 레이어의 출력마다 활성화함수(activation function)을 만들어 준다.
우리는 확률적 경사하강법(stochastic gradient descent)과
활성화 함수를 통한 로짓값을 이용하는 크로스엔트로피 손실함수를 사용할 것이다.
그리고 learning rate = 0.1로 설정한다.
function createModel() {
var model = tf.sequential()
model.add(tf.layers.dense({
units: 8,
inputShape: 2,
activation: 'tanh'
}))
model.add(tf.layers.dense({
units: 1,
activation: 'sigmoid'
}))
model.compile({
optimizer: 'sgd',
loss: 'binaryCrossentropy',
lr: 0.1
})
return model
}우리는 이 모델을 5000번 반복시켜보자.
await model.fit(xs, ys, {
batchSize: 1,
epochs: 5000
})await 키워드를 써준것을 보면 fit()함수가 모두 실행된 뒤(학습된 뒤)
Promise 객체 반환하면서 fulfilled 상태가 되는것을 확인하고 나서
predict( ) 함수를 실행시킬수 있게 된 거라고 볼 수 있다.
그리고 마지막으로 추론을 시켜보면,
model.predict(xs).print()우리는 [[0.0064339], [0.9836861], [0.9835356], [0.0208658]]이라는 출력값을 얻었고
학습이 잘 되었다는 것을 알 수 있다.
라는 것이 블로깅되어 있는 내용이고, 나는 옵티마이저를 adam으로 구현해보았다.
const tf = require('@tensorflow/tfjs');
// Optional Load the binding:
// Use '@tensorflow/tfjs-node-gpu' if running with GPU.
require('@tensorflow/tfjs-node');
xs = tf.tensor2d([[0, 0], [0, 1], [1, 0], [1, 1]])
ys = tf.tensor2d([[0], [1], [1], [0]])
function createModel() {
var model = tf.sequential()
model.add(tf.layers.dense({
units: 8,
inputShape: 2,
activation: 'tanh'
}))
model.add(tf.layers.dense({
units: 1,
activation: 'sigmoid'
}))
model.compile({
optimizer: 'adam',
loss: 'binaryCrossentropy',
lr: 0.1
})
return model
}
async function createNpredict(){
model = createModel();
await model.fit(xs,ys, {
batchSize: 1,
epochs: 5000
});
model.predict(xs).print();
}
createNpredict();
Epoch 4999 / 5000
eta=0.0 ===========================================================================================================>
30ms 7411us/step - loss=5.06e-4
Epoch 5000 / 5000
eta=0.0 ===========================================================================================================>
36ms 8935us/step - loss=5.05e-4
Tensor
[[0.0003238],
[0.9995046],
[0.9994414],
[0.0006391]]비슷하게 학습이 잘 된 것을 알 수 있다.
여기까지 간단하게 신경망을 구현해보았다.
이어서 Part.2에서 연재하도록 하겠다.
'TechTrend' 카테고리의 다른 글
| Mac에서 TensorFlow 가속화하기 (0) | 2021.01.26 |
|---|---|
| JavaScript에서도 pandas 같은 라이브러리를? Danfo.js를 소개합니다. (0) | 2021.01.23 |
| Teachable Machine과 TFLite를 활용한 음성인식 모델 만들기 (0) | 2021.01.19 |
| Tensorflow.js 사용하기(Part.3) (0) | 2021.01.15 |
| TensorFlow.js 사용하기(Part.2) (0) | 2020.02.17 |



