
TensorFlow.js 사용하기(Part.2)
- CNN Model
머신러닝을 위해서는 그래프생성에 대해 알아야하는데
이는 컴퓨터 공학에서 말하는 노드와 엣지로 구성되어있고
노드에 연산, 변수, 상수등을 정의하고 노드들간의 연결인 엣지를 통해 실제 텐서를
주고 받으면서 연산을 수행하게 되는데
TensorFlow.js는 이를 스스로 생성해주므로
이전 글에서와 같이 layer와 optimizer와 compile만 정의해주면 된다.
"컴파일??"
인공지능에서 이야기하는 '컴파일'이라는 단어는
기계어나 바이트코드로의 번역을 뜻하는 것이 아니라
모델이 효과적으로 학습하도록
여러 값들을 설정하고
역전파를 위한 오차함수를 결정하면서
학습할 준비를 모두 마치는 것을 의미한다.
이제 레이어를 정의 하기에 앞서 도식화된 다른 예시를 보자.

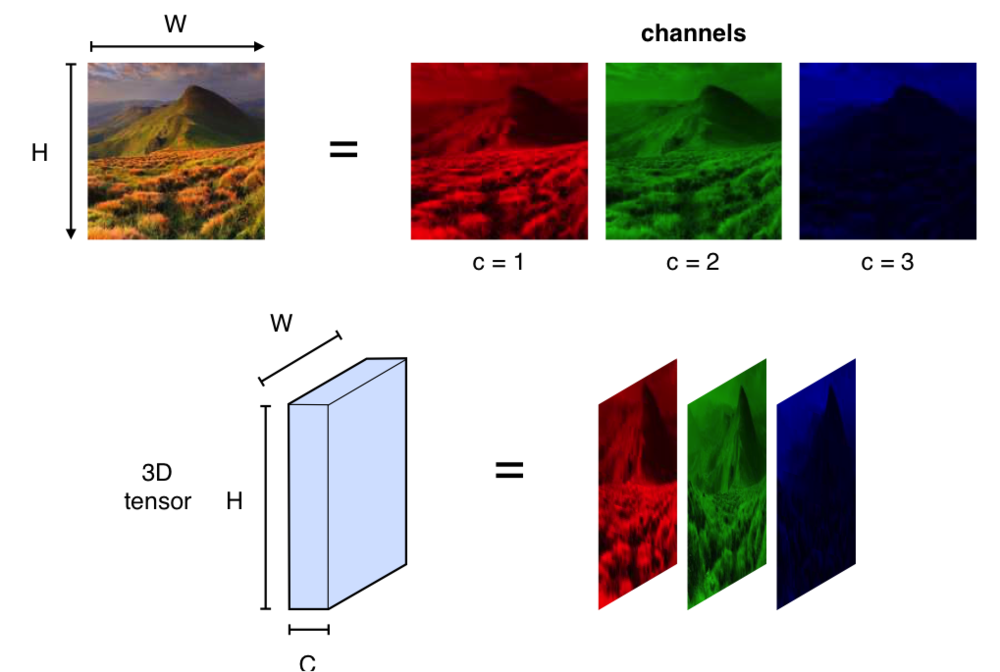
위 예시에서는 가로, 세로 6의 크기에 RGB로 3개의 채널(깊이)을 가진 데이터 입력이 들어온다.
여기서 가중치(파라미터)는 가로, 세로 3의 크기를 가진 하나의 커널(필터)이라고 한다.
왜 커널의 깊이에 대해서는 언급하지 않느냐는 궁금증이 생길 수 있는데
이는 데이터의 입력이 3의 깊이을 가지고 있기 때문에
커널의 깊이는 당연히 입력데이터의 깊이를 따라간다.
결과로 3개의 채널이 다시 더해지는 것을 보면
"하나의 이미지에서 rgb의 각 색마다 가중치를 부여하고, 다시 하나의 특징으로 나타나게 한다는 의미를 가진다."
그렇다면 커널의 개수에 대한 이해가 수월할 것이다.
자! 그럼 먼저 sequential model을 선언해준다.
model = tf.sequential();위와 같이 선언한 뒤,
[28, 28, 1]을 입력으로 하는 합성곱 layer를 정의한다.
const convlayer = tf.layers.conv2d({
inputShape: [28, 28, 1],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'VarianceScaling'
});예시에서의 입력은 28 by 28의 흑백 이미지(채널이 1개)이고
커널은 가로와 세로가 5이며, 커널의 개수는 8,
합성곱 연산을 수행할때 필터를 몇 칸씩 이동시킬지에 대한 값(strides)을 1로 적용했다.
그리고 들어오는 입력값과 연산하는 커널의 가중치를 초기화해주어야 하는데
이는 학습의 시작점이므로 중요하다고 할 수 있다.
여기서는 커널을 Variance Scaling으로 초기화해주는데
가중치 초기화 또한 무거운 주제이므로 기회가 된다면 따로 포스팅하겠다.
Variance scaling에 사용되는 방법에 해당하는 논문은 링크를 달아놓겠다.
http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf
이전에는 weight initializer와 같이 편리한 기능들이
keras에만 있던 기능인데 텐서플로우가 2.0대 버전으로 들어오면서
keras기능들을 내장하면서 들어온것으로 보여진다.
다른 초기화함수도 많으니 종류를 알아 놓으면 유용하다.
아래의 링크로 확인하면 된다.
https://keras.io/initializers/
다시 본론으로 돌아와
활성화 함수는 부정적인 값에 대해서는 0의 값으로 대체하는 relu를 적용했다.

이제 합성곱신경망을 모델에 적용해보자.
model.add(convlayer);이것이 TensorFlow.js 가 가지는 편리함이다.
모델은 compile만 해주면 입력에서
다음 레이어로의 크기를 특정하지 않아도 자동적으로 해준다.
이제 max-pooling, dense layers을 추가해보자.
const model = tf.sequential();
//create the first layer
model.add(tf.layers.conv2d({
inputShape: [28, 28, 1],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'VarianceScaling'
}));
// 예상 출력 텐서 : [1, 24, 24, 8]
//create a max pooling layer
model.add(tf.layers.maxPooling2d({
poolSize: [2, 2],
strides: [2, 2]
}));
// 예상 출력 텐서 : [1, 12, 12, 8]
//create the second conv layer
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'VarianceScaling'
}));
// 예상 출력 텐서 : [1, 8, 8, 16]
//create a max pooling layer
model.add(tf.layers.maxPooling2d({
poolSize: [2, 2],
strides: [2, 2]
}));
// 예상 출력 텐서 : [1, 4, 4, 16]
//flatten the layers to use it for the dense layers
model.add(tf.layers.flatten());
//dense layer with output 10 units
model.add(tf.layers.dense({
units: 10,
kernelInitializer: 'VarianceScaling',
activation: 'softmax'
}));출력텐서를 확인하기 위해 또 다른 레이어로 텐서만 추가하면 되지만
주의할 점은 입력이 [BATCH_SIZE, 28, 28, 1]의 형태이어야 한다.
참고로 BATCH_SIZE는 한번에 모델에 학습시킬 데이터의 수를 뜻한다.
여기서 합성곱 레이어의 형태를 짚고 넘어가자.
const convlayer = tf.layers.conv2d({
inputShape: [28, 28, 1],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'VarianceScaling',
});
const input = tf.zeros([1, 28, 28, 1]);
const output = convlayer.apply(input);이렇게 모델을 간단히 구성하여 [28, 28, 1]의 0행렬을 입력으로 주었더니
output 텐서를 확인해보면 [1, 24, 24, 8]의 형태인것을 알 수 있는데
공식을 사용하면 바로 확인해볼 수 있다.
const outputSize = Math.floor((inputSize - kernelSize/stide + 1);이렇듯 예시의 경우는 24가 나온다.
위에서 보면 flatten( )함수를 쓴 것을 볼 수 있는데

이는 다 차원배열을 1 차원 배열로 늘려주는 함수이다.
[BATCH_SIZE, a, b, c] 형태의 입력을
[BATCH_SIZE, a * b * c] (차원마다의 크기를 곱한)형태로 바꾸어준다.
예시의 학습시킬 데이터의 형식은 흑백사진이지만
컴퓨터에게는 컬러, 흑백, 픽셀등의 의미가 없다.

그래서 2 차원의 흑백사진을 1 차원 배열로
쭉! 늘려준 것이다.
이렇게 되면 마침내 output까지 왔다.
여기서 units 10이라 되어있는데
이것은 분류할 카테고리가 0~9까지
총 10가지라는 말이다.

실제로 이 모델은 mnist데이터셋에 손글씨를
분류하는데에 사용된다.
- Optimization and Compilation
이렇게 모델을 만들고 나면
처음 초기화해줬던 값들을 학습을 통해 최적화해줘야 한다.
최적화엔 Adam과 SGD 같은 다양한 방법론들이 존재한다.
아래 예시는 최적화기(Optimization)를 정의하는 방법이다.
const LEARNIING_RATE = 0.0001;
const optimizer = tf.train.adam(LEARNING_RATE);이렇게 최적화기들이 내장함수로 있어서 쉽게 이용할 수 있다.
위 예시에서는 learning rate을 입력으로 넣어주면
이제 모델을 구성(compile)할 세팅값들의 준비가 끝났다.
이제 모델을 구성해보자.
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});위의 코드와 이어서 출력과 정답을 예측할
오차함수로 크로스엔트로피를 이용하는
최적화기(adam)로 모델 구성을 마쳤다.
- Training
모델 컴파일링을 끝내고 이제 학습시킬 준비가 다 되었다.
학습을 시킬땐 fit( ) 함수가 쓰인다.
const batch = tf.zeros([BATCH_SIZE, 28, 28, 1]);
const labels = tf.zeros([BATCH_SIZE, NUM_CLASSES]);
const h = await model.fit(batch, labels,
{
batchSize: BATCH_SIZE,
validationData: validationData,
epochs: BATCH_EPOCHs
});BATCH_SIZE는 '해당 문제지에서 몇 문제씩 풀어보고 답안지를 볼 것인가?'를 의미한다.
epochs는 '같은 문제지를 몇 번 풀어볼 것인가?'를 의미한다.
fit( ) 함수의 첫번째 인자로
학습시킬 훈련 데이터셋의 배치가 들어가고,
두번째 인자로는
배치에 해당하는 정답셋을,
마지막인자로
몇 문제씩 풀어서 답안지를 볼 것인지에 대한 개수를,
중간 중간 잘 하고 있는 지를 검증할 테스트 문제들을,
이것들을 총 몇 번 해볼 것 인지에 대한 횟수를
정의하여 함수를 실행시키면 학습이 이루어진다.
- One Hot Encoding
보통 주어진 정답의 개수는 분류해야할 클래스의 수를 나타낸다.
예를 들어서 오렌지랑 사과, 딸기를 구분한다면
[오렌지, 사과, 딸기]로 생각하고
[1, 0, 0]을 오렌지,
[0, 1, 0]을 사과,
[0, 0, 1]을 딸기
위와 같이 해당하는 하나의 과일만을 '1'로 '불을 켠다'라는 의미로
one-hot-encoding이라 한다.

각 이미지 데이터들의 정답들은 정수이므로
1 차원 텐서로 정답들을 받아
oneHot( ) 함수의 인자로 넣으면
아래와 같이 편리하게 정답 데이터셋을 만들 수 있다.
const output = tf.oneHot(tf.tensor1d([0,1,0], 2);
//the output will be [[1,0], [0,1], [1,0]]
const output2 = tf.oneHot(tf.tensor1d([0,1,0,2,0,0,3], 5);
//the output2 will be
// [[1,0,0,0,0],
// [0,1,0,0,0],
// [1,0,0,0,0],
// [0,0,1,0,0],
// [1,0,0,0,0],
// [1,0,0,0,0],
// [0,0,0,1,0]]이렇게 연산에 용이하게 정답인 각각의 레이블(정수)들을 1 차원 텐서로 만들 수 있다.
BATCH_SIZE 수에 맞게 같이 슬라이스하여 학습시키는 것은 fit( ) 함수가 자동으로 해준다.
- Loss and Accuracy
학습을 마친 후에는
모델의 성능을 측정하기 위해
Loss와 Accuracy가 필요하다.
history 모듈을 사용하면 이전 결과들을 불어올 수 있다.
//h is the output of the fitting module
const loss = h.history.loss[0];
const accuracy = h.history.acc[0];참고로 fit( ) 함수에 입력으로 들어가는 validationData의 Loss와 Accuracy도 이용할 수 있다.
- Prediction
훈련이 끝난 모델과 좋은 loss와 accuracy를 얻었다면,
모델에게 보여주지 않은 데이터로 실험해볼 시간이다.
브라우저나 웹캡을 통해 이미지를 얻어서 훈련시킨 모델로 '예측'을 진행해 볼 수 있다.
첫번째로 이미지를 텐서로 전환해야한다.
//retrieve the canvas
const canvas = document.getElementById("myCanvas");
const ctx = canvas.getContext("2d");
//get image data
imageData = ctx.getImageData(0, 0, 28, 28);
//convert to tensor
const tensor = tf.fromPixels(imageData);캔버스는 html5에서 제공하는 API이므로 getContext( )로 컨택스트를 가져와 그 기능을 이용할 수 있다.
일반적으로 이미지가 컬러이므로 rgb에 해당하는 3개의 채널을 가진 3차원 텐서[28,28,3]일 것이다.
그러나 위에서 구현한 모델은 4개의 차원을 가지는 벡터를 입력으로 원하므로
expandDims( ) 함수를 통해 차원을 확장해주어야 한다.
const eTensor = tensor.expandDims(0);expandDims( ) 함수는 확장할 인덱스를 입력로 받는다.
예시로는 0 번째 차원이 확장되어 [28, 28, 3] 에서 [1, 28, 28, 3] 으로
텐서의 형태가 한 차원이 더 늘어난 모습을 볼 수 있다.
model.predict(eTensor);predict( ) 함수는 마지막 레이어의 값을 반환하는데
대개 softmax 활성화 함수의 출력이다.
이어서 Part.3에서 연재하도록 하겠다.
'TechTrend' 카테고리의 다른 글
| Mac에서 TensorFlow 가속화하기 (0) | 2021.01.26 |
|---|---|
| JavaScript에서도 pandas 같은 라이브러리를? Danfo.js를 소개합니다. (0) | 2021.01.23 |
| Teachable Machine과 TFLite를 활용한 음성인식 모델 만들기 (0) | 2021.01.19 |
| Tensorflow.js 사용하기(Part.3) (0) | 2021.01.15 |
| TensorFlow.js 사용하기(Part.1) (0) | 2020.02.14 |



